
What is Snowflake Query Acceleration Service?

Photo by Paweł Fijałkowski from Pexels7 minute read.
What is Snowflake Query Acceleration Service?
Snowflake Query Acceleration Service (QAS) is a feature built into all Snowflake Virtual Warehouses which can dramatically improve query performance by automatically adding additional compute resources to complete large table scans. It’s almost like a “go faster” button for very queries which scan massive data volumes, and best of all it’s a pay-for-use feature, meaning you can easily boost SQL query performance without increasing costs. This can lead to order of magnitude query performance gains on SELECT, INSERT and CREATE TABLE AS commands.
How does Query Acceleration Work?
Before a query starts, Snowflake estimates whether there are sufficient machine resources to execute the query, and if the cluster is too busy, the query may be queued. This can lead to a real challenge when executing unpredictable workloads which include short running queries that complete within seconds alongside others that need to scan billions of rows and take minutes or even hours to complete. The longer running queries not only lead to frustration, but they can block other queries from running, and the only sensible option is normally to scale up to a larger warehouse for example scaling from a SMALL to an X-LARGE cluster.
While huge queries running on an X-LARGE cluster with 16 database servers will undoubtedly run faster, this is not an ideal solution, as it can lead to higher overall running costs as the short running queries don't make full use of the 128 virtual CPUs, but the cluster is charged at a rate of 16 credits per hour.
Ideally, we'd like Snowflake to run a SMALL virtual warehouse, but automatically detect when a huge query needs more resources and temporarily provide additional database servers to complete the work, and then release the compute resources when they are no longer needed.
In line with Snowflake’s consumption based cost model, you’d only pay for the additional compute resources when you need them, while Snowflake takes care of dynamically adjusting compute resources to fit the workload. That’s exactly what QAS actually does.
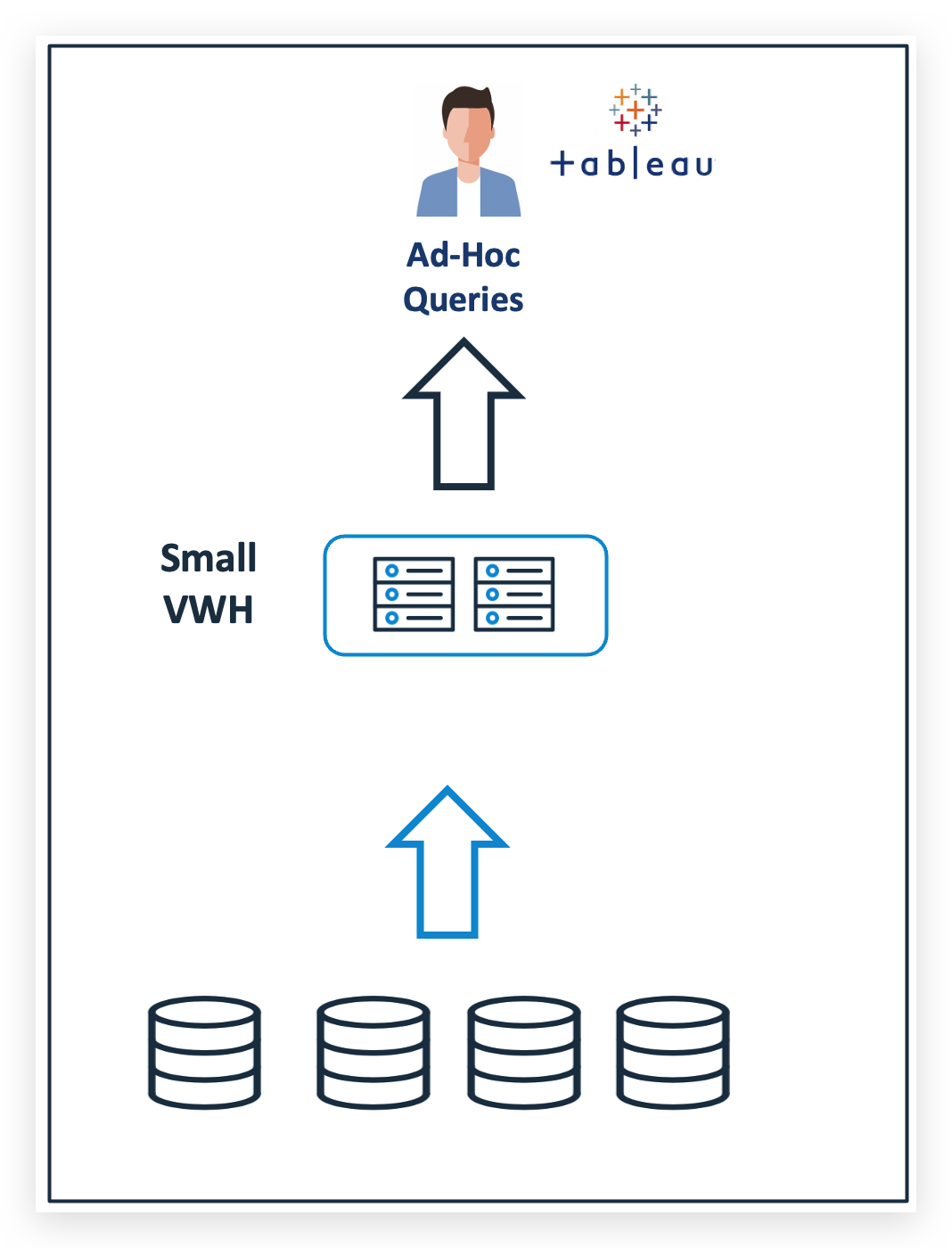
The diagram above illustrates the situation whereby users are running queries on a SMALL virtual warehouse with the risk of query queuing and poor query performance. However, once Query Acceleration Service is enabled, Snowflake will automatically offload work to QAS servers up to the specified scale factor.
The diagram below illustrates the situation when Snowflake detects a massive query that will scan gigabytes of data. In this case the warehouse size remains at SMALL (charged at two credits per hour), but additional database servers are requested from QAS to take on the heavy lifting. This means that not only will the huge query return results more quickly, but it frees up resources on the SMALL cluster to execute other short running queries from other users. Overall, it’s less expensive than scaling up to a larger warehouse and leads to more efficient use of resources.
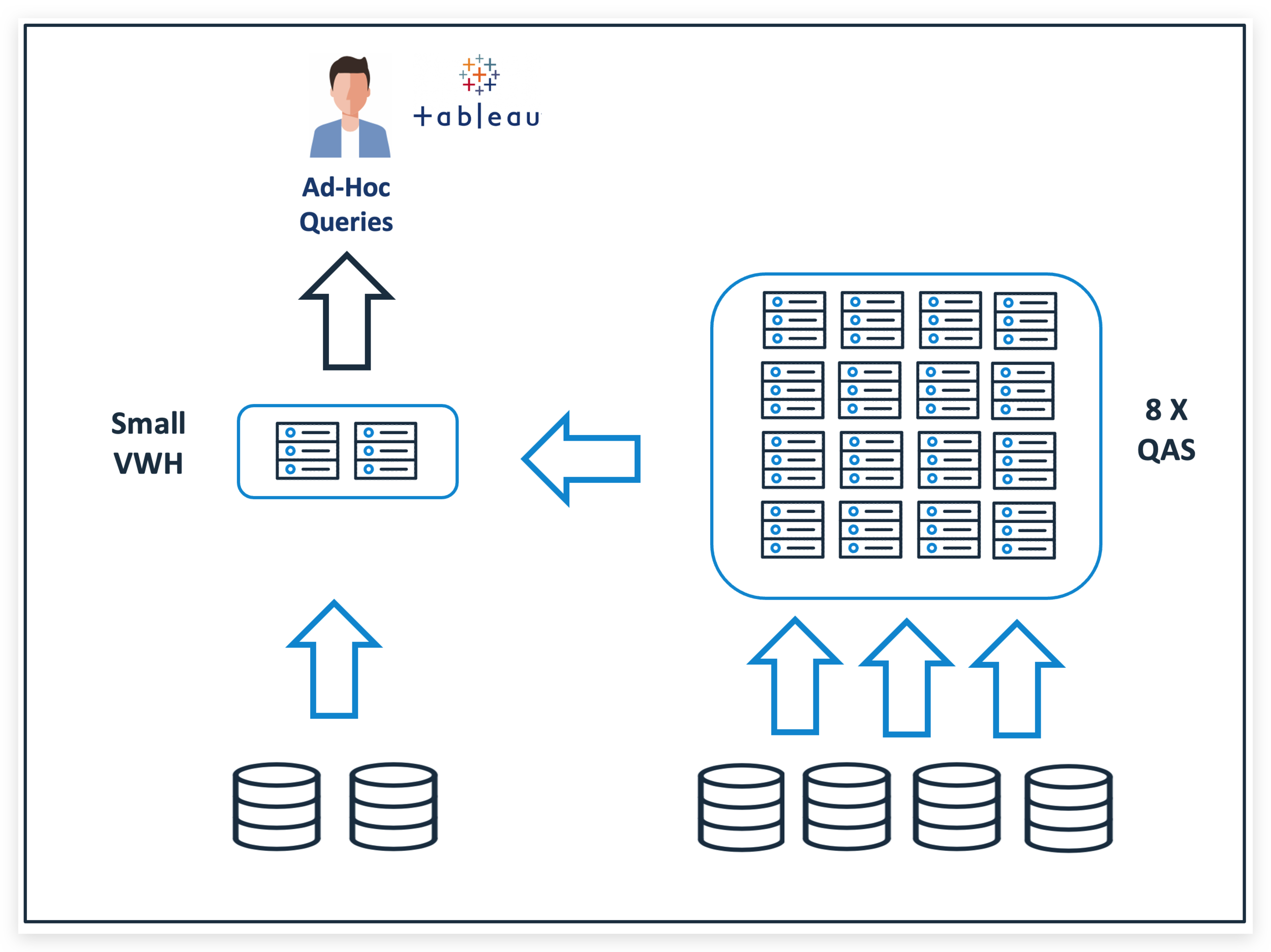
Effectively the Query Acceleration Service acts like a powerful additional cluster that’s temporarily available to deploy alongside your existing warehouses and when needed, takes on some of the grunt work. In common with all other serverless operations on Snowflake, the QAS resources are charged on a per-CPU-second basis, so you only ever pay for the compute resources actually used, but large volume queries are completed much faster.
How to enable Query Acceleration Service?
By default acceleration service is not enabled, but it can be quickly deployed against a warehouse using :-
alter warehouse query_vwh enable_query_acceleration = true query_acceleration_max_scale_factor = 16;
The above query enables QAS and automatically allows the virtual warehouse to allocate up to 16 times the original warehouse size. This means (for example), and XSMALL warehouse with just one database server can automatically scale up to 16 servers. Likewise, the same settings on a LARGE warehouse with 8 database servers would automatically scale up to 16 times the size or a total of 128 servers. This makes it possible to run unimaginably large queries against massive data volumes on servers larger than currently supported by Snowflake. You can even set the scaling factor to zero which gives Snowflake a free hand to scale up QAS as large as it the query needs.
Which queries benefit from Query Acceleration Service?
To answer this question you need to consider the technical challenge QAS is trying to solve. Consider a typical Snowflake query as follows:
select store, sum(sales) from sales_data where region = 'SOUTH' and year = 2021 group by store;
If we assume the SALES_DATA table holds billions of rows the operations are likely to include:
Fetch the data from storage
Filter out the data for 2021 and SOUTH region
Sort the data by STORE
Aggregate (sum) the data
Collate the results and present them to the user
Currently query acceleration will only help with steps 1 and 2 which include fetching the data and filtering out the results although in later releases, this may be extended to include additional steps.
Of course in a table with terabytes of data, a query can could spend 80% of the time just fetching and filtering the results and clearly any reduction in the time taken will significantly improve overall query performance. However, consider the following query instead:
select store, sum(sales) from sales_data group by store;
Similar to the first SQL, the query above will also fetch terabytes of data. However, unlike the previous example, this query doesn’t filter out any of the rows (a task which could be offloaded to QAS). Therefore it’s unlikely QAS would improve query performance as a SMALL warehouse which would be overloaded with the sort and aggregation steps needed while also holding on to the QAS resources.
For this reason, even though QAS has been switched on for a given warehouse, it will only be used when:
The query needs to scan large volumes of data (gigabytes to terabytes)
The query includes filtering which significantly reduces the volume of data processed.
If the query doesn’t filter down the data to a small enough volume to be processed on the given warehouse, then QAS may not actually be used.
This means QAS is best suited to mixed workloads with a few outlier queries which fetch large data volumes but also filter out results before aggregation.
How does the Scale Factor work?
The scale factor sets a maximum limit on the number of QAS database servers which can be allocated by a warehouse and it's always a multiple of the existing warehouse size. The table below shows the number of database servers by T-Shirt size and the corresponding cost per hour.

Therefore the SCALE FACTOR is a multiple of the number of database servers. For example, if a Query Acceleration factor of 16 were applied to a 3X-LARGE, this would deploy up to 16x64 database servers or a total of 1,024 QAS servers.
Be aware that the scaling factor is a maximum value, and Snowflake will decide how many servers to allocate up to this limit. Once allocated to a virtual warehouse, these servers can be used by any queries on the same virtual warehouse, although as only the fetch and filtering operations are executed on QAS, the queries won't benefit from the warehouse cache.
Also be mindful of the fact that Snowflake independently determines whether to use QAS on a query-by-query basis. This means, for example, the same query executed on an X-LARGE warehouse may not use QAS whereas the same query on an X-SMALL perhaps might. Snowflake automatically determines whether the the query would benefit from using the Acceleration Service, and will only deploy this if it’s estimated to improve query performance and overall throughput.
Benchmarking Query Acceleration Performance
To test to effect of Query Acceleration Service, we executed a series of queries using the TCP benchmark tables delivered with every Snowflake deployment. The following query was executed against different size tables varying from 1.3TB to 10TB of data, with or without using QAS.
select d.d_year as "Year" , i.i_brand_id as "Brand ID" , i.i_brand as "Brand" , sum(ss_net_profit) as "Profit" from snowflake_sample_data.tpcds_sf10tcl.date_dim d , snowflake_sample_data.tpcds_sf10tcl.store_sales s , snowflake_sample_data.tpcds_sf10tcl.item i where d.d_date_sk = s.ss_sold_date_sk and s.ss_item_sk = i.i_item_sk and i.i_manufact_id = 939 and d.d_moy = 12 group by d.d_year , i.i_brand , i.i_brand_id order by 1, 4, 2 limit 200; order by 1, 4, 2 limit 200;
In the first test against the TCP 10 data with a STORE_SALES table of around 1.3TB, the elapsed time was reduced from 3:04 minutes to 41 seconds - around 4.5 times faster using a scaling factor of zero on an SMALL warehouse.
Running the same query against the 10TB sized STORE_SALES table reduced elapsed time from 10:06 minutes to just 45.4 seconds - 13.5 times faster using the same SMALL warehouse and a scaling factor of zero - allowing Snowflake to use as many resources as possible.
Be aware however, not every query will benefit from Query Acceleration Service, and Snowflake will decide when to make use of QAS based upon the volume of data scanned and the availability to QAS resources. This can lead to unexpected variation in query performance, even when the same query is executed.
Monitoring Query Acceleration
The following SQL can be used to fetch the most recent cost records from the query acceleration service. This shows both the credit cost of the operations and the number of bytes scanned.
SELECT * FROM table(information_schema.query_acceleration_history( date_range_start=>dateadd(h, -1, current_timestamp)));
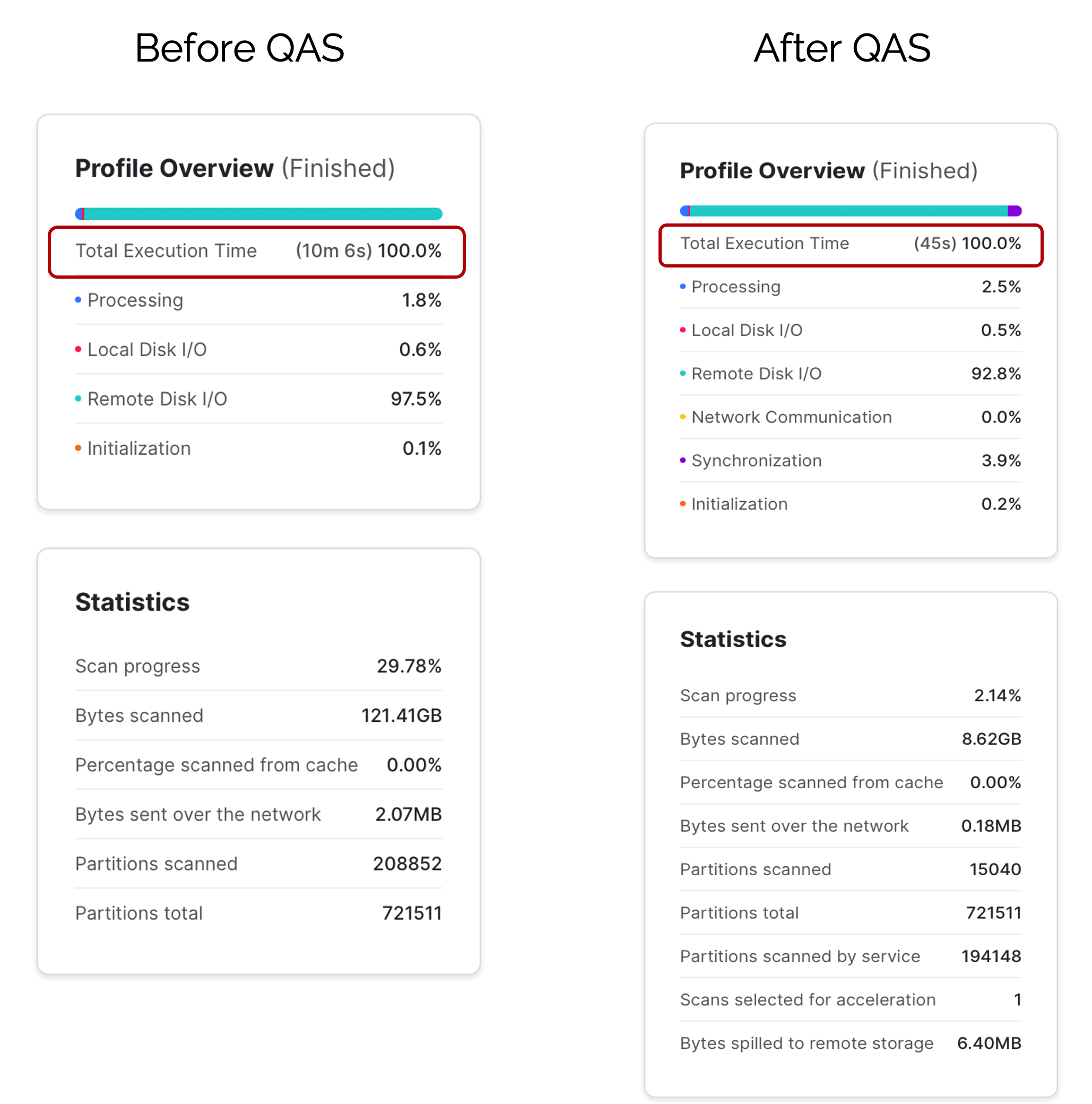
Finally, the screen shot below shows the query profile of the query above which shows an incredible performance gain from over 10 minutes to 45 seconds for the same cost.
The SMALL warehouse processed just 15,040 micro-partitions while the Query Acceleration Service processed 194,148 entries which led to the13 times massive improvement in execution time on the same query and the same size warehouse.
Conclusion
While Snowflake advise allocating similar size workloads on the same warehouse to maximise efficient use of resources this is often not possible and many customers simply allocate different warehouses to different teams. In addition to potentially inefficient use of resources (as you need to allocate a warehouse size for the largest workload), it can also reduce overall throughput as smaller queries are queued while long running table scans are being executed.
The Snowflake Query Acceleration Service goes a long way to resolving the situation and it's as efficient as it is simple to use. Once enabled, Snowflake transparently offloads large table scan and filter operations to the QAS servers and dynamically allocates resources as needed. Best of all, in addition to being remarkably simple to deploy, it quietly works in the background automatically improving query performance were it can, and the user is charged purely for the resources consumed.
Once again, you can get your results back up to 13 times faster at zero additional cost, as Snowflake demonstrates both an incredible ability to innovate while also delivering a service that's incredibly simple and easy to use.
Notice Anything Missing?
No annoying pop-ups or adverts. No bull, just facts, insights and opinions. Sign up below and I will ping you a mail when new content is available. I will never spam you or abuse your trust. Alternatively, you can leave a comment below.
Disclaimer: The opinions expressed on this site are entirely my own, and will not necessarily reflect those of my employer.

John A. Ryan